This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Switch branches/tags
Branches Tags
Could not load branches
Nothing to show
Could not load tags
Nothing to show
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Cancel Create
- Local
- Codespaces
HTTPS GitHub CLI
Use Git or checkout with SVN using the web URL.
Work fast with our official CLI. Learn more.
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
Парсинг в Python за 10 минут!
There was a problem preparing your codespace, please try again.
Источник: github.com
Парсинг Aliexpress с nodejs, puppeteer и RuCaptcha
Привет всем начинающим Node.js-разработчикам. В сегодняшней статье разберем реальный кейс парсинга на Node.js (с использованием puppeteer, cheerio и ruCaptcha). Я подробно распишу, как сделал простой парсер товаров на Aliexpress. Этот пример вы сможете легко изменить для ваших задач.
Дисклеймер: все, что вы прочитаете в этой статье, написано исключительно в образовательных целях, автор статьи (как и администрация сайта techrocks.ru) не несет никакой ответственности за возможное использование информации незаконным путем.
Начнем с теории:
Что такое парсинг
Парсинг/скрапинг — автоматический сбор информации по заданному признаку. В качестве источников могут выступать социальные сети, интернет-порталы и вообще любые другие ресурсы в интернете. Информация, собранная с помощью парсинга в последующем может быть использована для наполнения собственной базы данных, анализа и т.п.
Какие задачи можно решить с помощью парсинга?
- Сбор данных, например, сбор списка товаров, их свойств, фотографий, описаний, цен и т.п.
- Анализ цен у конкурентов, их контент.
- Изучение пользовательской активности на сайте.
В этой статье я буду парсить Aliexpress и соберу данные о товарах заданного магазина.

Инструменты, которые мы будем использовать:
- Puppeteer — nodejs библиотека, которая предоставляет высокоуровневое API для программного управления браузером на движке Chromium. Подробнее о puppeteer можно узнать по ссылке.
- Cheerio — библиотека, которая позволяет работать с HTML по тому же принципу, что и в jQuery (доступны те же селекторы и т.п.)
- Chalk — библиотека, которая позволит нам красиво выводить результаты работы нашего скраппера в консоль
- ruCaptcha — сервис распознавания капчи. Позволит нам обходить капчи при большом количестве одновременных запросов.
Структура проекта
Структура проекта будет довольно простой — сразу мы создадим файл package.json (с помощью команды npm init). Далее создадим 3 каталога:
Парсер сайта настраиваем самостоятельно. Парсим сайты интернет-магазинов: картинки,цены,описание
data — каталог, где мы будем хранить собранные данные с Aliexpress
handlers — каталог, где будут храниться обработчики
helpers — каталог, где будут лежать дополнительные функции
Установим все зависимости:

Пишем код
Создадим index.js в корне проекта и начнем писать код:
import cherio from ‘cherio’; import chalk from ‘chalk’; import < arrayFromLength >from ‘./helpers/common’; import < getPageContent >from ‘./helpers/puppeteer’; const SITE = ‘https://www.Aliexpress.com/store/5410049/search/1.html’; // constant with link to catalog
Создаем helper для работы со страницами каталога
Мы импортировали основные зависимости, создали константу с ссылкой на первую страницу каталога, который будем парсить и импортировали нашу первую вспомогательную функцию arrayFromLength из папки helpers. Ее написанием сейчас займемся.
Функция arrayFromLength будет принимать на вход число страниц, и будет возвращать массив со значениями этих страниц. Создадим файл common.js в папке helpers и напишем следующий код:
export function arrayFromLength(number) < return Array.from(new Array(number).keys()).map(k =>k + 1); >
Создаем функцию для загрузки контента страницы
Для загрузки страниц с нам потребуется написать функцию getPageContent, которая будет принимать на вход url страницы и возвращать ее содержимое. Для этого будем использовать puppeteer. В папке helpers создадим файл puppeteer.js со следующим содержимым:
import puppeteer from ‘puppeteer’; export const LAUNCH_PUPPETEER_OPTS = < args: [ ‘—no-sandbox’, ‘—disable-setuid-sandbox’, ‘—disable-dev-shm-usage’, ‘—disable-accelerated-2d-canvas’, ‘—disable-gpu’, ‘—window-size=1920×1080’, ], >; export const PAGE_PUPPETEER_OPTS = < networkIdle2Timeout: 5000, waitUntil: ‘networkidle2’, timeout: 3000000, >; export async function getPageContent(url) < try < const browser = await puppeteer.launch(LAUNCH_PUPPETEER_OPTS); const page = await browser.newPage(PAGE_PUPPETEER_OPTS); await page.goto(url, PAGE_PUPPETEER_OPTS); const content = await page.content(); browser.close(); return content; >catch (err) < throw(err); >>
Про конфиги puppeteer (константы LAUNCH_PUPPETEER_OPTS, PAGE_PUPPETEER_OPTS) можно почитать в документации — это тема отдельного занятия. Обратите внимание, я обернул код функции getPageContent в try-catch блок и пробрасываю ошибку наверх (в вызывающий код) — обрабатываться она будет в нашем основном методе main в index.js.
Разбираем страницу каталога
Начнем писать основной метод для разбора каталога — для этого в index.js мы создадим функцию main, которая и будет делать основную работу. Это будет самовызывающаяся функция, которая будет формировать корректные url-ы страниц для парсинга, загружать их с помощью puppeteer и с помощью cherio доставать нужные нам поля.
Функцию main мы обернули в try-catch блок, чтобы отлавливать все ошибки в одном месте и корректно их обрабатывать. В нашем случае мы будем выводить ошибку в консоль.
(async function main() < try < for(const page of arrayFromLength(CATALOG_PAGE_LENGTH)) < const url = `$/$.html`; const pageContent = await getPageContent(url); const $ = cherio.load(pageContent); const items = []; $(‘#node-gallery .items-list .item’).each((i, item) => < console.log(i); const url = $(‘.detail h3 a’, header).attr(‘href’); const title = $(‘.detail h3 a’, header).attr(‘title’); const price = $(‘.cost b’, header).text(); items.push(< url, title, price >); >); await listItemsHandler(items); > > catch (err) < console.log(chalk.red(‘An error has occurred’)); console.log(err); >>)();
Функция main проходится по страницам каталога и загружает каждую из них. После этого, с помощью cherio мы разбираем содержимое страницы, проходимся по всем карточкам товаров каталога и получаем url страниц с подробным описанием, название товара и его цену).
Пишем обработчик listItemsHandler для разбора страницы товара
Далее нам необходимо написать функцию-обработчик listItemsHandler, которая будет получать массив данных с товарами, дополнять их необходимыми полями и сохранять в файл (в рамках текущей статьи мы рассмотрим вариант с сохранением в файл, на практике вероятнее всего вы заходите сохранять результаты в базу данных). Для этого создадим файл с названием listItemsHandler.js в папке handlers и напишем следующий код:
import cherio from ‘cherio’; import chalk from ‘chalk’; import < getPageContent >from ‘../helpers/puppeteer’; export default function listItemsHandler(data) < try < for (const initialData of data) < console.log(chalk.green(‘Getting data from: ‘ + chalk.green.bold(initialData.url))); const detailContent = await getPageContent(initialData.url); const $ = cherio.load(detailContent); const productTitle = $(‘.product-main .product-info .product-title-text’).text(); const productPrice = $(‘.product-main .product-info .product-price-value’).text(); const productSizes = $(‘.product-main .product-info .product-sku .sku-property-list’).map( (i, item) =>$(‘.sku-property-item .sku-property-text span’, item).text() ); const productImageUrl = $(‘.product-main-wrap .image-cover .maginfier-image’).attr(‘src’); await saveData(< initialData.url, productTitle, productPrice, productSizes, productImageUrl, >); > > catch (err) < throw err; >>
В этом методе мы проходимся по массиву товаров, загружаем страницу с детальным описанием этого товара, с помощью cheerio получаем дополнительные данные (в нашем случае, цену, название, размеры и URL изображения) и сохраняем полученный объект в файл. Осталось написать функцию saveData, которая и будет отвечать за сохранение.
Сохраняем разобранные данные в файл
Создадим файл saver.js в папке handlers со следующим содержимым:
import path from ‘path’; import fs from ‘fs’; import chalk from ‘chalk’; export default async function saveData(data) < const < title >= data; const fileName = `$.json`; const savePath = path.join(__dirname, ‘..’, ‘data’, fileName); return new Promise( (resolve, reject ) => < fs.writeFile(savePath, data, err => < if (err) < return reject(err); >console.log(chalk.blue(‘File was saved successfully: ‘ + chalk.blue.bold(fileName) + ‘n’)); resolve(); >); >); >;
Подключаем ruCaptcha
На данном этапе у нас получился полностью готовый несложный парсер на node.js, но есть одна существенная проблема, которая не позволит вам собрать данные. Все дело в капче, которую показывает Aliexpress (и, кстати, не только AliExpres) при большом количестве отправленных запросов. Эту проблему удобнее всего решить, используя RuCaptcha — сервис ручного распознавания капчи с решениями для разных языков программирования (в том числе и для JS). Подробную документацию можно посмотреть по ссылке.

Для работы с капчами я буду использовать npm-пакет rucaptcha-client.
Создадим файл captchaSolver.js в папке handlers и напишем следующий код:
import Rucaptcha from ‘rucaptcha-client’; export async function solveCaptcha(imageUrl) < try < const rucaptcha = new Rucaptcha(xxxxxxxxxxxxxxx); // ваш API-ключ // Если ключ API был указан неверно, выбросит RucaptchaError с кодом // ERROR_KEY_DOES_NOT_EXIST. Полезно вызывать этот метод сразу после // инициализации, чтобы убедиться, что ключ API указан верно. const balance = await rucaptcha.getBalance(); const answer = await rucaptcha.solve(imageUrl); return answer.text; >catch (err) < throw err; >>;
Работает RuCaptcha очень просто:
- Вы получаете персональный API-ключ в настройках вашего аккаунта.
- Отправляете запрос на сервер ruCaptcha с вашим API-ключом и параметрами вашей капчи. Список поддерживаемых параметров можно посмотреть здесь.
- В ответ получаем ID задачи (Captcha ID)
- Отправляем на сервер ruCaptcha полученный Captcha ID и получаем решенную капчу.
В нашем случае npm-пакет инкапсулирует некоторые из этих шагов и нам достаточно дождаться выполнения метода rucaptcha.solve
Источник: techrocks.ru
Как парсить и экспортировать данные с Aliexpress
Aliexpress это источник огромного количества полезных данных для предпринимателей, ведь там собрана информация практически о всех категориях популярных товаров, от детских товаров и одежды до техники и электроники. Буквально любой товар, который вы можете себе представить, с большой вероятностью найдётся на Aliexpress. Ежемесячно этот сайт посещают более 450 миллиона раз и совершают тысячи покупок, а самое главное для предпринимателей, что можно совершенно бесплатно собрать информацию о товарах и использовать его для анализа рынка.
Порсинг Aliexpress даст вам представление о самых популярных товарах, ценах на них, их качестве и производительности, скидках, а также позволит сравнить все эти показатели с показателями на других сайтах в реальном времени.
Способы сбора данных
Написание скрипта
Если у вас имеются навыки программирования, вы можете написать собственный скрипт для парсинга, например, с помощью библиотеки BeautifulSoup для языка Python. Однако, структура сайта может меняться с течением времени, и для сохранения работоспособности скрипта его необходимо будет регулярно переписывать. По этой причине такой подход займёт слишком много времени, а если вы решите нанять для выполнения этой работы, то ещё и потребует много денег.
Сервис для мониторинга цен
Этот способ, в отличии от предыдущего, не требует так много времени, знаний и ресурсов, так как практически вся работа будет выполняться автоматически, хороший инструмент для парсинга может собрать всю нужную вам информацию за минимальное количество времени и предоставить вам её в удобном формате.
Как собрать информацию с Aliexpress с помощью All Rival
Отфильтруйте на Aliexpress товары, информация о которых вам интересна.
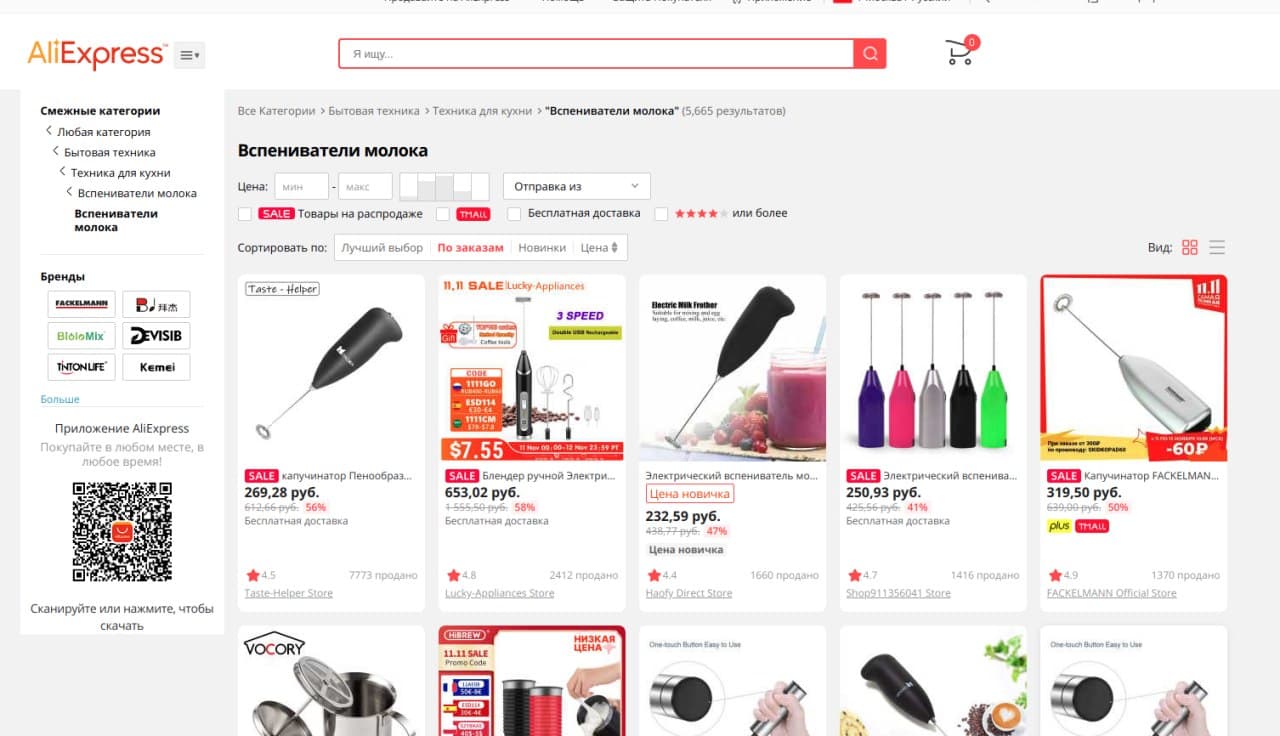
Скопируйте полученную ссылку, вставьте её в поле для ссылок и начните поиск товаров на странице, после выберите только интересующие вас товары, или все найденные и добавьте их в список для мониторинга.
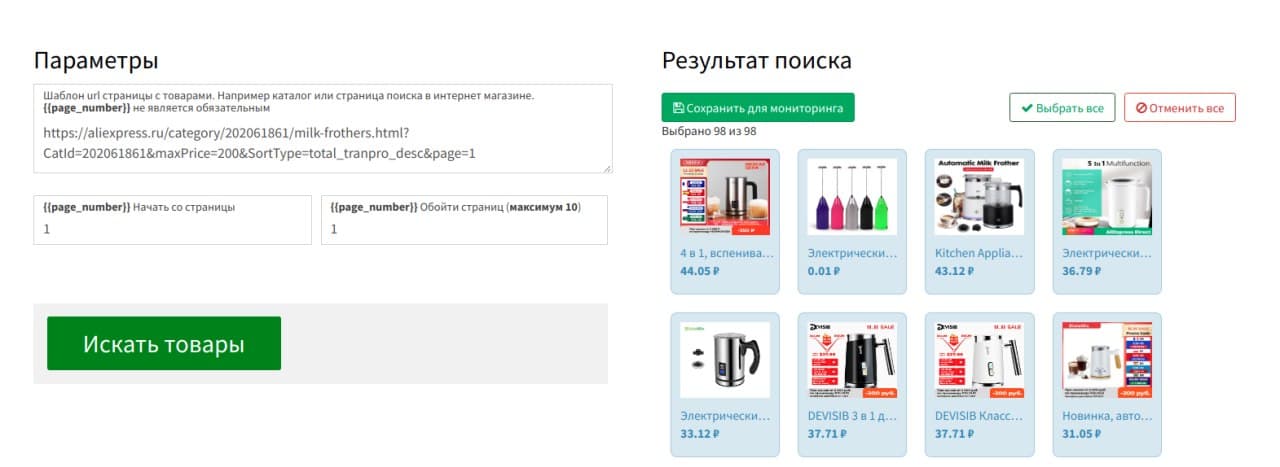
Дождитесь окончания мониторинга выбранных товаров и скачайте отчёт с результатами анализа в виде электронной таблицы или любом другом удобном для вас формате.
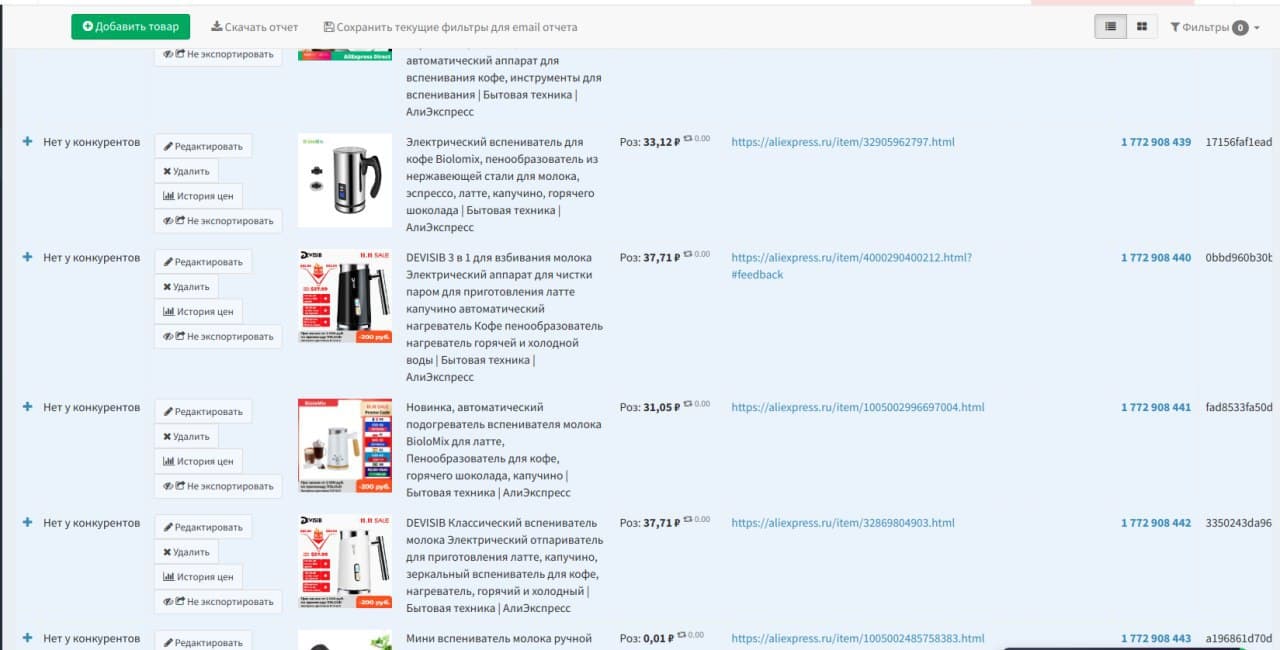
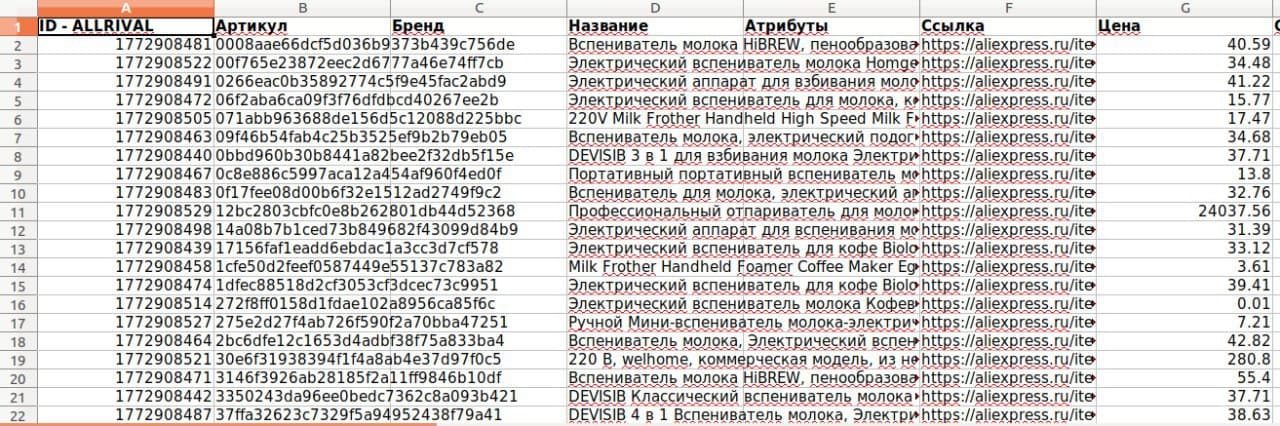
Парсинг Aliexpress поможет вам получить преимущество в конкурентной борьбе за счёт постоянного доступа к информации о популярных товарах с крупнейшей в мире торговой площадки, а All Rival позволит вам облегчить процесс сбора данных за счёт большого функционала для мониторинга и интуитивно понятного интерфейса расширения для Google.
Источник: allrival.com